Random variable – variable that takes on numerical values determined by the outcome of a random experiment. Usually denoted by X
Probability distribution – expresses probability that a continuous random variable takes on value X=x
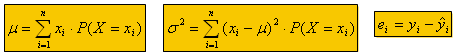
- Adding a constant to a variable shifts the distribution
- Multiplying by a constant changes the dispersion of a variable (if <1σ reduces, if >1σ increases)
To compute the probability for a normal random variable, convert X~N(μ, σ2) to Z~N(μ, σ2):
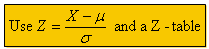
Point Prediction – If data is independent, the best prediction is the mean. If data is not independent (runs test significant at <0.05) then Xt+1 = Xt + μchange + εt
Runs Test
- Few runs -> cyclical time series
- Many runs -> oscillating time series
- Medium # of runs -> independent time series
- When we predict for independent series (=μ of series) the confidence interval is a multiple of σ
- When we predict for non-independent time series (=μchange + εt) the confidence interval is a multiple of the variance (σ2) {e.g. X70 ~ N(X68 + 2μchange , 2σchange2)}
A random walk exists is the changes from period to period are independent and normally distributed
Estimating μ and σ {X representative of μ, s2 representative of σ2)
- If X ~ N(μ, σ2) then X ~ N(μ, σ2/n)

Linear Regression (α + ßx) + εt with εt iid N(μ, σε2)
Make distance from each point to the estimated line as small as possible. Minimize Σεt2

4 Basic Assumptions and how to check them:
- linearity – non-linear pattern in x/y plot; u-shaped pattern in the Residuals vs. Fit plot
- constant variance – look for funnel in the Residuals vs. Fit plot
- independence – pattern in time series plot; runs test
- normality – histogram of e’s (residual = e)
Assuming X is independent (data set) implies the e’s are independent. Must check this.
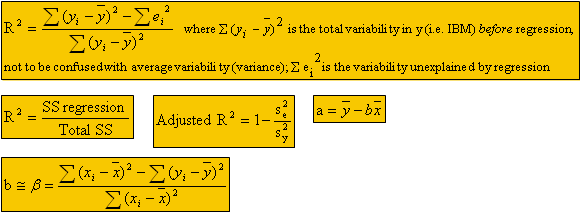
Specification bias – exists when an explanatory variable that should be included in regression is left out. {if a coefficient doesn’t make sense it could be due to specification bias}
Understanding the Regression Output:
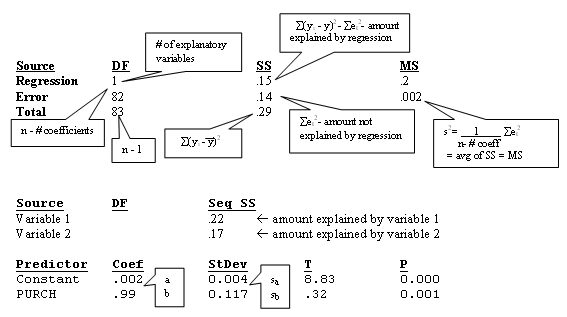
In regressions, error terms don’t accumulate (predictions)
Coefficients are random variables because they depend on sample of points
Any time you standardize using an estimate you get a t-distribution not a z-distribution

- Dummy variables are useful when the # of data points isn’t sufficient for multiple single regressions
- Interpret regression model using dummy variables as multiple parallel regression lines where the coefficients are the distance between the lines
- Baseline is the dummy variable that is left out (intentionally) when running the regression
- Best prediction of true regression α + ßx = ε is a + bx (ε=0)
Confidence Intervals
2 components of prediction error:
- (α + ßx) – (a + bx)
- ε
- the ore uncertainty about the 2 sources of error, the more uncertain the prediction is and therefore a wider confidence interval
- Minitab gives a 95% interval
Time Series with Trend
Pattern consists of:
- Trend – model with Time variable
- Seasonal component – model with multiple dummy variables
- Short-term correlation (cyclical) – model w/ Yt-1
- Unpredictable component (ε)
To modify the model to account for non-constant variance, run a regression model for % change in variable (i.e. sales) {this is like a non-independent time-series point prediction}
Leading indicators can improve the model BUT are not useful for predicting
It is important to know how close b is to ß:
The sampling distribution for b is b ~ N(ß, σb2)

Hypothesis Testing: (H0: ß=0 HA: ß<>0) – useful for determining which variables have explanatory power
Type I Error – say ß=1 when ß=0 (reject H0 when H0 is true)
Type II Error – say ß=0 when ß=1 (accept H0 when H0 is false)
Procedure:
- Collect sample
- Compute b
- Compare to critical t-value
- Reject H0 if (b/sb) > tcritical
We’re choosing a cutoff value such that pr(Type I error) = 0.05 (α)
Each coefficient has a t-distribution with (n – total # coefficients) degrees of freedom (tn-#, α)
- If one-sided decision (i.e. HA: ß>0), use α as given percentage
- If two-sided decision (i.e. HA: ß>0), use α as ½ of the given percentage
Click to Add the First »