The relational model is based on set theory in mathematics. A relation is nothing but a “table” (as perceived by us) that consists of tuples (rows) and attributes (columns). The values of attributes fall into a known domain or legal values (For example, SSN consists of values from 000000000 to 999999999 or Age is between 0 and 125). These domains enforce some degree of data integrity (so that users don’t enter meaningless values. For example, number of students in class to be -20 or 3.26). The primary key is a unique identifier for the table. The primary key cannot take a NULL value (means a record cannot exists with a unique identifier. For example, SSN is a primary key for an Employee. One cannot enter an employee’s information without his/her SSN). First, we will discuss the process of normalization and then get to integrity rules (apart from the above domain integrity rule).
Normalization
Normalization theory deals with reducing undesirable properties such as redundancy, and minimizing INSERT, DELETE and UPDATE anomalies. (Some of the anomalies are a result of redundancy).
The degree of normalization is defined by normal forms. The normal forms in an increasing order of normalization are first normal form (1NF), second normal form (2NF), 3NF, Boyce Codd Normal form (BCNF), 4NF and 5NF. In general, 3NF is considered good enough. In certain instances, a lower level of normalization is desirable (e.g., where queries take enormous time to execute).
In order to understand normalization, one needs to understand how attributes are related (or what is called functional dependencies). For example, SSN determines a person’s name. We say that Name is functionally dependent on SSN; typically represented by SSN ® Name.
Example: Consider a database that is intended to keep track of faculty and courses offered. An extremely simple way of maintaining data is given below:
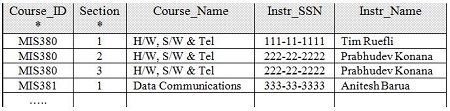
In the above example, assume Course_ID and Section form the (composite) primary key. That is, primary key uniquely determines the tuple (record) (note – there can be more than one candidate key in a table). The functional dependencies in the above table are as follows:
Course_ID → Course_Name
Course_ID, Section → Instr_SSN
Course_ID, Section → Instr_Name
Instr_SSN → Instr_Name

The above table is in INF since the attribute set contains atomic values (values cannot be broken down into smaller elements). However, there are many problems:
- If an instructor is not teaching any course, he/she will not be represented in the database (INSERT anomaly).
- If MIS381 is deleted, we lose all the information of Instructor “Anitesh Barua” (DELETE anomaly).
- If we have to rename the Course_name for MIS380, we need to update every record that has MIS380 (DELETE anomaly).
We can now normalize the above table since one of the attributes is partially dependent on the primary key (Course_ID → Course_Name). In other words, Course_Name is not completely dependent on Course_ID and Section (the primary key). We can now make two tables from the above:

The above two tables are said to be in 2NF since every (non-key) attribute is fully dependent on the primary key. This has minimized some of the problems discussed earlier (UPDATE anomaly). However, we can normalize further since Instr_Name is transitively dependent on the Primary key (that is, even if there is no direct link between the primary key and Instr_Name, it can be derived transitively from (1) Course_ID, Section → Instr_SSN; and (2) Instr_SSN → Instr_Name). Therefore, we can split the above tables into three tables as below:
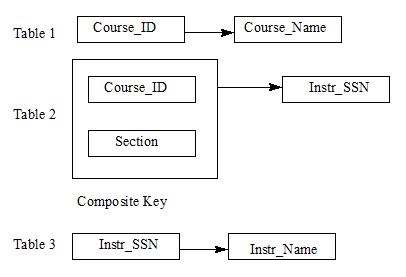
The above set of tables is said to be in 3NF, that is, every non-key attribute is non-transitively dependent on the primary key. This further eliminates some of the problems such as INSERT and DELETE anomalies (and also the redundancy). Other normal forms such as BCNF, 4NF and 5NF can be neglected (In fact, the above relations are in BCNF).
Integrity Rules
Apart from domain integrity there are two types of integrity rules in relational model: Entity integrity and Referential Integrity. Entity integrity implies that a primary key cannot accept nulls (If the primary key is a composite key, that is, more than one attribute forms a primary key, then no component of a primary key can accept nulls). In the above example, Course_ID and Section must be entered. Referential integrity is more involved and best explained through the above example. Consider TABLE 2 that has attributes Course_ID and Instr_SSN. Assume Course_ID MIS380 is entered in TABLE 2 but has no corresponding entry in TABLE 1. Similarly, Instr_SSN 111-11-1111 is entered in TABLE 2 but has no entry in TABLE 3. This creates many problems. For example, you will never know what is the name of the course_ID MIS380 or the instructor’s name who teaches MIS380 section 2. To avoid such problems, we define something called FOREIGN KEY.
TABLE 2 has two foreign keys that are primary keys of other tables. Course_ID and Instr_SSN are foreign keys. If there are no corresponding entries in TABLE 1 and/or TABLE 3 for Course_ID and Instr_SSN respectively then one cannot make any entry in TABLE 2. Through FOREIGN Keys we can enforce many types of integrity rules. If any change is made in TABLE 1 or 3 the corresponding entries in TABLE 2 are also changed (Cascade on update). If entries are deleted in TABLE 1 or 3 then corresponding entries in TABLE 2 can be also deleted (cascade on delete). If you don’t want to delete in TABLE 1 or 3 if there are entries in TABLE 2 then one can enforce RESTRICT on delete.